杠杆炒股,股票融资!

发布日期:2024-04-07 15:24 点击次数:181
裁剪:LRS
【新智元导读】师法东谈主类阅读历程,先分段选录再回忆,谷歌新框架ReadAgent在三个长文档阅读领会数据集上赢得了更强的性能,灵验高下文普及了3-20倍。
基于Transformer的谣言语模子(LLM)具有很强的话语领会才调,但LLM一次巧合读取的文本量仍然受到极大摈弃。
除了高下文窗口较小外,LLM的性能会跟着输入履行长度的增多而下落,即便输入履行未跳跃模子的高下文窗口长度摈弃亦然如斯。
比拟之下,东谈主类却不错阅读、领会和推理很长的文本。
LLM和东谈主类在阅读长度上存在相反的主要原因在于阅读措施:LLM逐字地输入精准的履行,况且该历程相对被迫;但过于准确的信息常常会被淡忘,而阅读历程更珍贵领会纰谬的重心信息,即不研讨准确单词的履行能记念更万古候。
东谈主类阅读亦然一个互动的历程,比如回答问题时还需要从原文中进行检索。
为了贬责这些摈弃,来自Google DeepMind和Google Research的商讨东谈主员提倡了一个全新的LLM系统ReadAgent,受东谈主类怎么交互式阅读长文档的启发,将灵验高下文长度增多了20倍。

受东谈主类交互式阅读长文档的启发,商讨东谈主员将ReadAgent收场为一个浅显的指示系统,使用LLMs的高档话语功能:
1. 决定将哪些履行存储在记念片断(memory episode)中;
2. 将记念片断压缩成称为重心记念的轻便片断记念,
3. 若是ReadAgent需要提醒我方完成任务的联系细节,则遴荐活动(action)来查找原始文本中的段落。
在实验评估中,比拟检索、原始长高下文、重心记念(gist memories)措施,ReadAgent在三个长文档阅读理受命务(QuALITY,NarrativeQA和QMSum)上的性能线路齐优于基线,同期将灵验高下文窗口彭胀了3-20倍。
ReadAgent框架
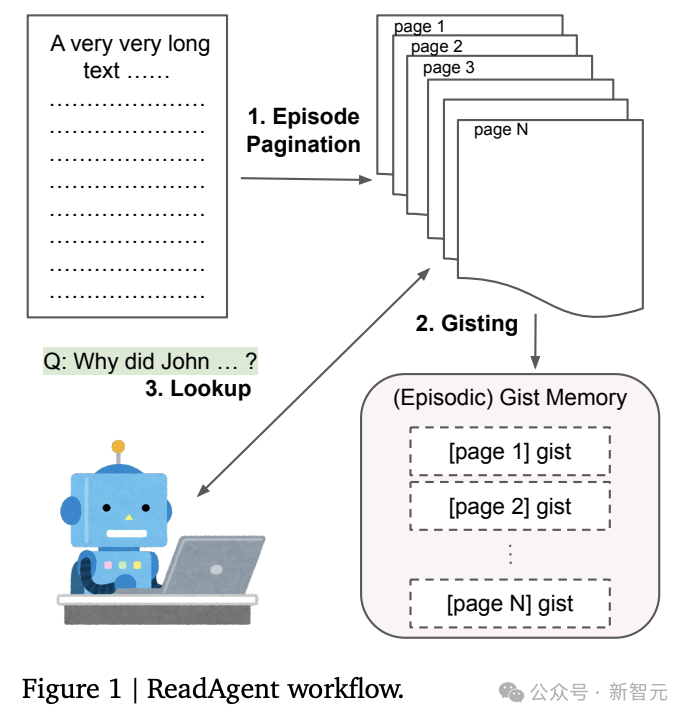
1. 重心记念(gist memory)
重心记念是原始长高下文采文本块的短重心的有序勾通,构建gist记念有两个门径:分页(pagination)和记念撮要(memory gisting)。
片断分页(episode pagination)
当ReadAgent阅读长文本时,通过弃取暂停阅读的位置来决定在记念片断中存储哪些履行。

每一步齐会为LLM提供部分文本,从上一个暂停点运行,并在达到最大单词数摈弃时收尾;指示LLM弃取段落之间的哪个点将是当然的暂停点,然后将前一个和刻下暂停点之间的履行视为一个episode,也不错叫作念页(page)。
记念撮要(memory gisting)
对于每一页,指示LLM将真是的履行缩小为重心或选录。

2. 并行温规章交互查找
由于重心记念与页联系,是以只需指示LLM来找出哪一页更像是谜底,并在给定特定任务的情况下再次阅读,主要有两种查找战术:同期并行查找通盘页面(ReadAgent-P)和每次查找一个页面(ReadAgent-S)。
ReadAgent-P
比如说,在问答任务中,频繁会给LLM输入一个不错查找的最大页数,但也会相似其使用尽可能少的页面,以幸免无须要的贪图支出和侵略信息(distracting information)。

ReadAgent-S
规章查找战术中,模子一次央求一页,在决定张开(expand)哪个页面之前,先检讨之前张开过的页面,从而使模子巧合拜访比并行查找更多的信息,预期在某些特等情况下线路得更好。

但与模子的交互次数越多,其贪图本钱也越高。
3. 贪图支出和可彭胀性
片断分页、记念撮要和交互式查找需要迭代推理,也存在潜在的贪图支出,但具体支出由一个小因子线性不停,使得该措施的贪图支出不会输入长度的增多而剧烈普及。
由于查找和反映大多是条款重心(conditioned gists)而非全文,是以在并吞高下文中的任务越多,本钱也就越低。
4. ReadAgent变体
当使用长文本时,用户可能会提前知谈要贬责的任务:在这种情况下,股票投资撮要门径不错在指示中包括任务形容,使得LLM不错更好地压缩与任务无关的信息,从而提高恶果并减少侵略信息,即条款ReadAgent
更通用的任务修复下,在准备撮要时可能不知谈具体任务,或者可能知谈提倡的重心需要用于多个不同的任务,举例回答对于文本的问题等。
因此,通过摒除注册门径中的任务,LLM不错产生更历害有用的撮要,代价是减少压缩和增多侵略严防力的信息,即非条款ReadAgent。
这篇论文中只探讨了无条款修复,但在某些情况下,条款修复可能更有上风。
迭代撮要(iterative gisting)
对于一段很长的事件历史,举例对话等,不错研讨通过迭代撮要来进一步压缩旧记念来收场更长的高下文,对应于东谈主类的话,旧记念更纰谬。
实验完了
商讨东谈主员评估了ReadAgent在三个长高下文问答挑战中的长文档阅读领会才调:QuALITY、NarrativeQA和QMSum。
固然ReadAgent不需要锻真金不怕火,但商讨东谈主员仍然弃取在锻真金不怕火集上斥地了一个模子并在考证、测试和/或斥地集上进行了测试,以幸免过拟合系统超参数的风险。
采取的模子为指示微调后的PaLM 2-L模子。
评估宗旨为压缩率(compression rate, CR),贪图措施如下:
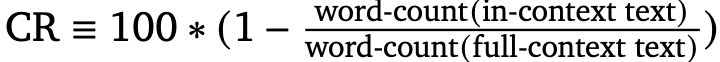
LLM评分器
NarrativeQA和QMSum齐有一个或多个开脱步地的参考回话,频繁使用诸如ROUGE-F之类的语法匹配度量来评估。
除此除外,商讨东谈主员使用自动LLM评分器来评估这些数据集,看成东谈主工评估的替代措施。

上头两个指示中,「严格LLM评分器指示」用于判断是否存在精准匹配,「许可LLM评分器指示」用于判断是否存在精准匹配或部分匹配。
基于此,商讨东谈主员提倡了两个评价宗旨:LLM-Rating-1(LR-1)是一个严格的评估分数,贪图通盘示例中精准匹配的百分比;LLM-Rating-2(LR-2)贪图精准匹配和部分匹配的百分比。
长高下文阅读领会
QuALITY
QuALITY是一个多选问答任务,每个问题包含四个谜底,使用来自多个不同开首的文本数据。
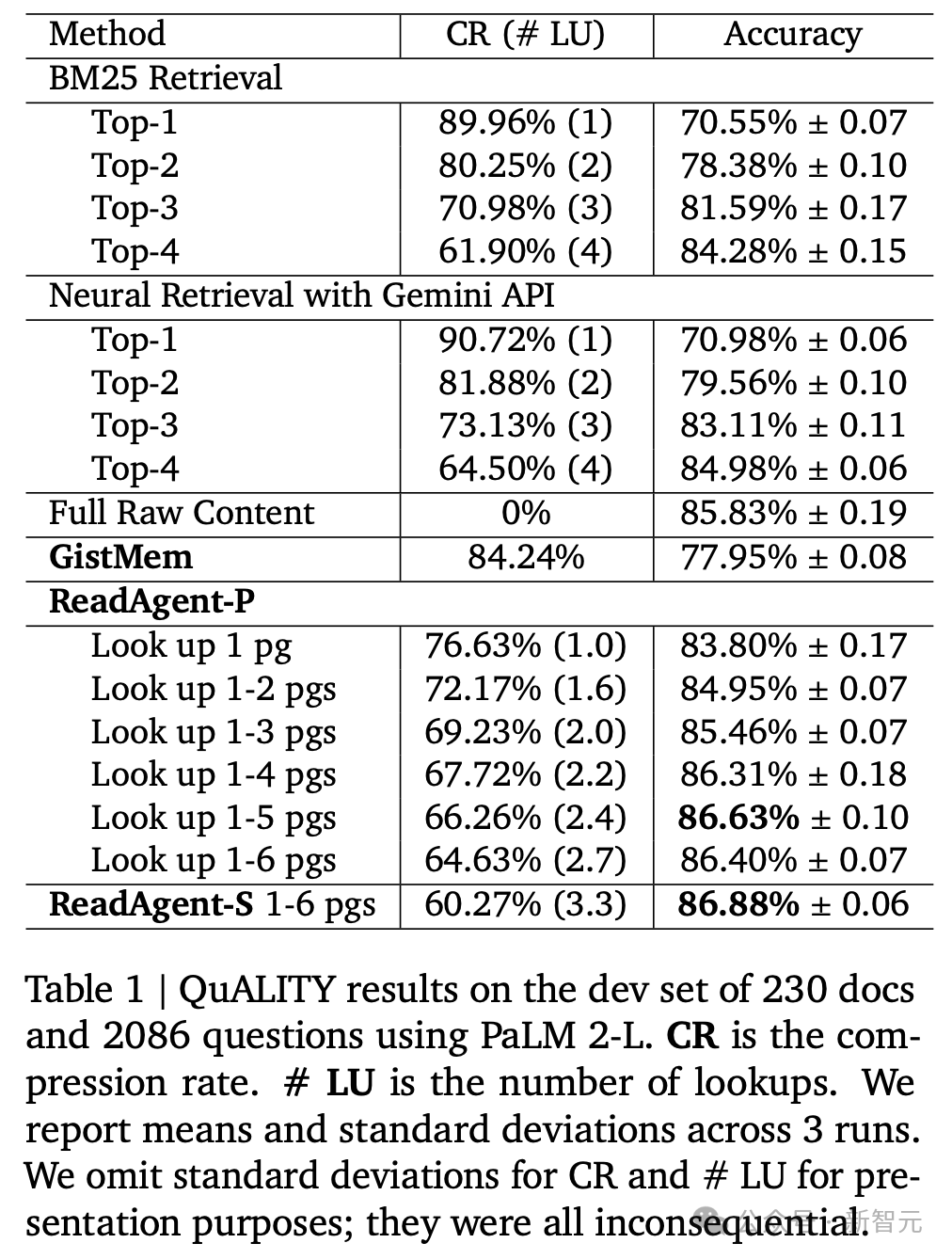
实验完了领路,ReadAgent(查找1-5页)收场了最佳的完了,压缩率为66.97%(即撮要后高下文窗口中不错容纳3倍的token)。
当增多允许查找的最大页数(最多5页)时,性能会无间提高;在6页时,性能运行略有下落,即6页高下文可能会增多侵略信息。
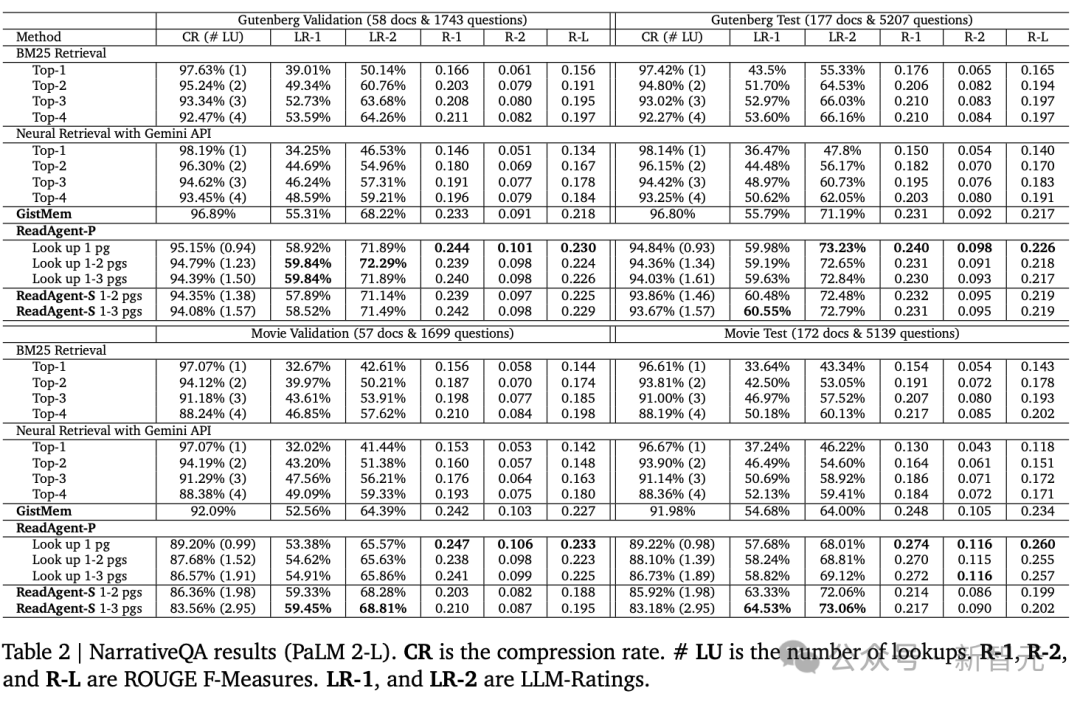
NarrativeQA
在三个阅读领会数据蚁集,NarrativeQA的平均高下文长度最长,为了将gists放入高下文窗口,需要彭胀页面的尺寸大小。
撮要对Gutenburg文本(竹素)的压缩率为96.80%,对电影脚本的压缩率为91.98%
QMSum
QMSum由各式主题的会议记载以及联系问题或阐述构成,长度从1,000字到26,300字不等,平均长度约为10,000字,其谜底是开脱步地的文本,法式的评估宗旨是ROUGE-F
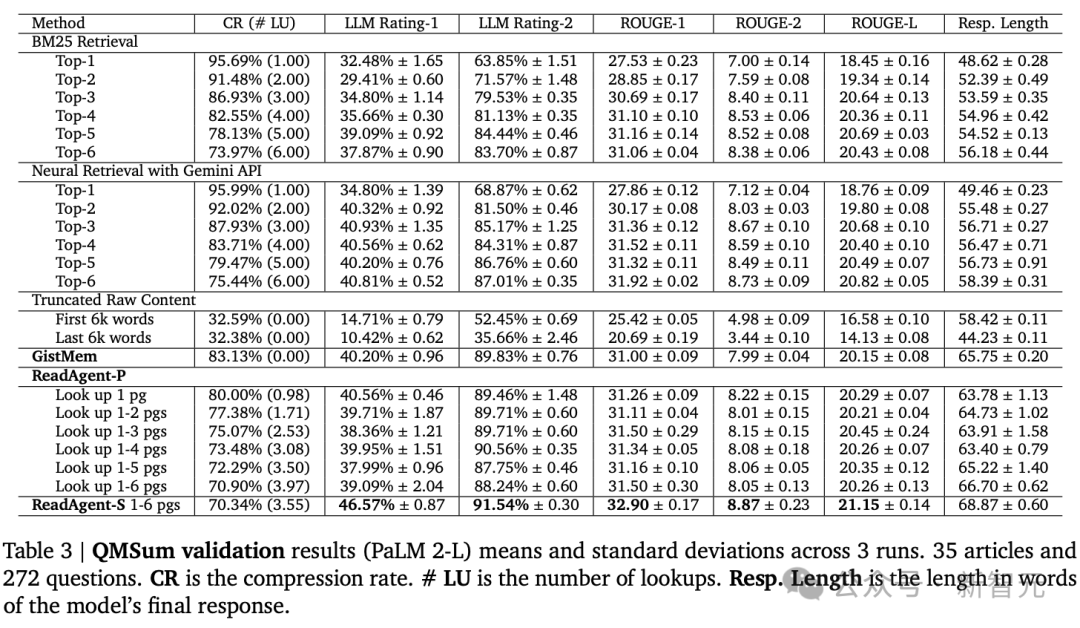
不错看到性能跟着压缩率的诽谤而提高,因此查找更多页面的时候常常比查找更少页面的时候作念得更好。
还不错看到ReadAgentS大大优于ReadAgent-P(以及通盘基线),性能调动的代价是检索阶段的央求数目增多了六倍。